1) Implementing algorithms on top of rational numbers.
2) Introducing rounding phases to algorithm, usually in a post processing stage.
For example lets look at a pretty popular example, based on the one from Hobby's paper.
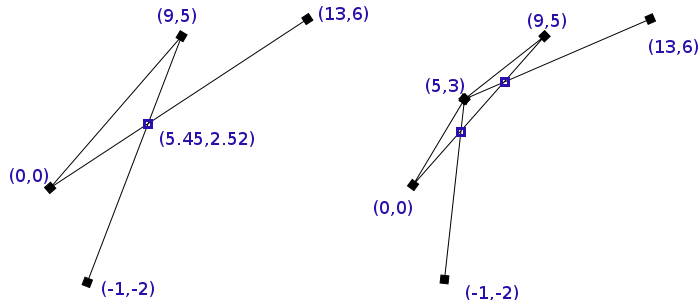 In this example we have three line segments with one intersection between them. Now if we round up the intersection to integer coordinates two new intersections are introduced - ones that are completely incorrect. Although we don't round up that heavily the following example scales into infinity as you uniformly divide coordinates by the same number.
In this example we have three line segments with one intersection between them. Now if we round up the intersection to integer coordinates two new intersections are introduced - ones that are completely incorrect. Although we don't round up that heavily the following example scales into infinity as you uniformly divide coordinates by the same number.There are two main reasons why this behavior is so undesirable for graphics.
1) It produces obviously incorrect results.
2) Optimized algorithms often break down due to those inconsistencies.
The first one is actually less important - on this scale the degeneration of our results is likely to produce errors that won't have too significant effects on what you see on the screen. Two is a lot more severe. For example a lot of the more popular geometrical algorithms includes a step of finding segments containing a point. Assuming that a segment has floating point coordinates and the point is, as well, in floating point coordinates - the containment test will very quickly break down as the limited precision will hit the computations. So there's no way to reliable perform that test, due to which all those algorithms will simple fail. As a result, an incredibly small rounding error will likely cause a complete failure of an algorithm and because of that small error you won't see any results on the screen. That's a serious problem.
Going back to the solutions to this problem. John Hobby wrote a paper entitled "Practical Segment Intersection with Finite Precision Output". Algorithm which he introduced in that paper has since been named "snap rounding". Numerous papers have been written since about this algorithm, some of the better ones include "Iterated Snap Rounding" by Halperin and Packer and "Snap Rounding Line Segments Efficiently in Two and Three Dimensions" by Goodrich and Guibas. The basic principle of this algorithm is very simple; every event point is computed within some tolerance square. Every tolerance square has its middle computed and all events that we encounter, whose coordinates fall withing already existing tolerance square are "bent" in a way that changes their coordinate to be equal to the middle of the tolerance square. This technique works surprisingly well.
The second method, often employed by professional grade geometrical software, involves replacing float/double by a custom "rational" number class. They produce mathematically correct results, which is ideal. The reason why we can't really even consider them is that they're about 30+ times slower than doubles.
Now the reason I went on this rant is that I've been testing results of my new algorithm for rasterizing polygons, which involves decomposition, and even though on paper the algorithm was always correct and the unit tests were all passing, the algorithm was falling apart in some cases. I've spent a while going through my intersection detection code, snap rounding implementation and couldn't find anything. Then I looked at some of the data files I had and they were only in limited precision of .001 which is not even close enough to being precise enough for floating point intersections/coordinate systems. Feel my pain =)
7 comments:
You also can arbitrarily extend the precision of IEEE-754 floating-point using only floating-point operations until there's enough to satisfy the relations you need. See Jonathan Shewchuk's triangle mesh generator for an explicit example. The trade-off is that the time to execute a geometry query or op is no longer constant.
Zack, a good introduction to numerical robustness issues in geometric predicates is Christer Ericson book.
His presentation at last year's GDC was fairly interesting, and apparently he repeated it this year. The ppt on his site is perfectly readable with oo.org.
As you know, when it comes to drawing polygons, I prefer not to do tesselation to avoid the precision issues entirely, and use stencil methods instead. With the speed of current GPUs, it's usually faster, but in the most convoluted cases. And if you don't have a decent GPU you are better off using a scanline algorithm anyway.
Well im a user of vector graphics, i i realy lock foward to se some development in the opensource vector precision front. I come form a autocad world, and precision is their game.
but now in inkscape and most all other opensource vector drawing tools and renderes i have lots of problems, the major ones come from what you talkd about and they are very visible wen for exemple i do somthing like, object to path that it the drawing is smaler than lets say 10 px it will get totaly broken with small mistakes and lots of uneaded data.
The secong error is gradient precision if for exemple you make 3 excatly the same 100% alpha to 0% apha gradients and place them all on top onother and set general alpha to a level of lets say 5% you dont get a linear result what you get is a several bands of the same alpha level and that ruins the efect.
@anonymous: yes, thanks for pointing it out :)
@Ignacio: take the following two simple examples:
poly0 poly1
(with data points for them recorded as x,y coordinates for all in: data ) now lets say those things need to be filled with a simple linear gradient. I'm not aware of any method that would render those. Even with shaders you have a serious problem because containment test done for every pixel will be very expensive plus you'll have to count on the fact that implementors won't use any shortcuts on GL_EXT_framebuffer_multisample (like antialiasing only edges) to hope for any kind of antialiasing on those objects.
Scanconversion of polygons is a technically unbound operation and since the X server is single threaded right now rendering of huge polygons could starve all clients - which is why we force client side trapezoidation before at the moment :)
Zack, the stencil method to draw polygons operates in two different passes. First you render to the stencil only, disabling writes to the color and depth buffer. The stencil mode depends on the filling mode of the polygon and on whether you have a previous clipshape.
The polygon is rendered linearly, you choose one vertex and draw a triangle for every edge. For the xor filling mode you only need one bit of stencil and set the stencil to increment. This mode is pretty fast, and GPUs usually render fragments 4 times faster when in this mode.
Once you have the stencil mask ready, you only have to render a quad on top of it. In this second pass you only write to the color buffer and use the stencil test to do the containment test. You only write the color when the stencil is not zero. This is very efficient and happens before the evaluation of the fragment program. Then you can use any fragment program to implement gradients and texture reads.
In any case, I understand that implementing this in the X server is complicated, but using this method in Qt, instead of the existing glut polygon render should be fairly easy.
The main problem is the extreme overdraw that could happen in some shapes, this can be reduced by breaking up the polygon in smaller pices, but that would increases the complexity of the algorithm. Antialiasing quality depends directly on what the GPU supports, and with 4xAA you only get 16 level of greys. You can render to a bigger texture and downsample to achieve higher aa quality.
I don't understand your statement about scan conversion. Can't you yield at the scanline level?
Maybe we should continue the conversation by email, writting in this small box is really tedious...
Yes, I agree with most of what you said except that you keep forgetting the major problem that you can't render the primitives we want. It's not in which way do we render them that's the question, it's how do we render them at all. They're complex polygons, so you need to decompose into at least simple polys because OpenGL just can't handle them otherwise. Using GLU Nurbs tessellator is really slow which is why we're experimenting with other methods. Try for example to render the second poly from the two I gave above with odd-even rule.
Also note that any kind of decomposition will yield precision problems here, no matter whether we're doing triangulation, trapezoidation or simply untangle the polygon.
But yeah, lets continue via email, I think I still have an email from you that I haven't responded to =)
I don't forget that, avoiding the triangulation is the main purpouse of using the stencil to draw arbitrary polygons. The stencil method does not require any decomposition, nor any intersection test, nor any expensive CPU work.
Post a Comment