In general all (at least Open Source) hardware accelerated vector graphics frameworks break up complex polygons in the process of tessellation. Like I mentioned in a few blogs before this process turns out to be quite complicated when trying to make it robust and fast. Ignacio's method beautifully avoids both problems.
So now to the method - the core idea is that we render to the stencil buffer and use it to correctly render the final polygon. So to use the Odd-Even fill rule we enable stencil writes and set up the stencil mask with glStencilMask(0x01) call. Next we make sure that the on passing the pixels are inverted with glStencilOp(GL_KEEP, GL_KEEP, GL_INVERT);. Then we can set the function and reference value for stencil testing by calling glStencilFunc(GL_ALWAYS, 0, ~0). Now we just render the vertices of our complex polygons as, for example triangles (fans would be just as suitable). Finally, we can enable color writes, disable stencil writes and enable stencil test and render a quad with the min/max coordinates of our polygon.
The method is awesome, as it (in theory) doesn't involve any kind of client side computations (besides a trivial min/max test) and (again in theory) operates in whole on the hardware. A wonderful sideeffect of all of this is that we avoid robustness issues that tessellation introduces.
To test this method I wrote today an application to compare different methods of rendering complex polygons (full client side rasterization, trapezoidation on X11 with Xrender, triangulation with OpenGL and finally stencil tests with OpenGL). So far Ignacios stencil method is by far the best. A sample result showing rendering of a rather complex (1000+ vertices) polygon follows, first client side rasterization:
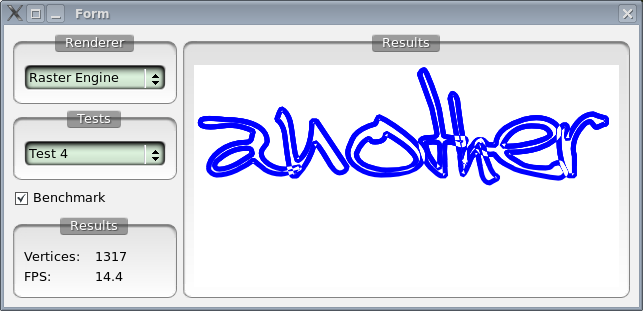
And now Ignacio's method:

Finally an insane polygon I created for testing robustness (intersections at distances smaller than the resolution of doubles) and speed (it has segments with 100+ vertical vertices falling on a scanline). The new method can actually handle it correctly and with 100000+ vertices we still get usable performance. Pretty amazing, so thanks Ignacio for letting me know about this!
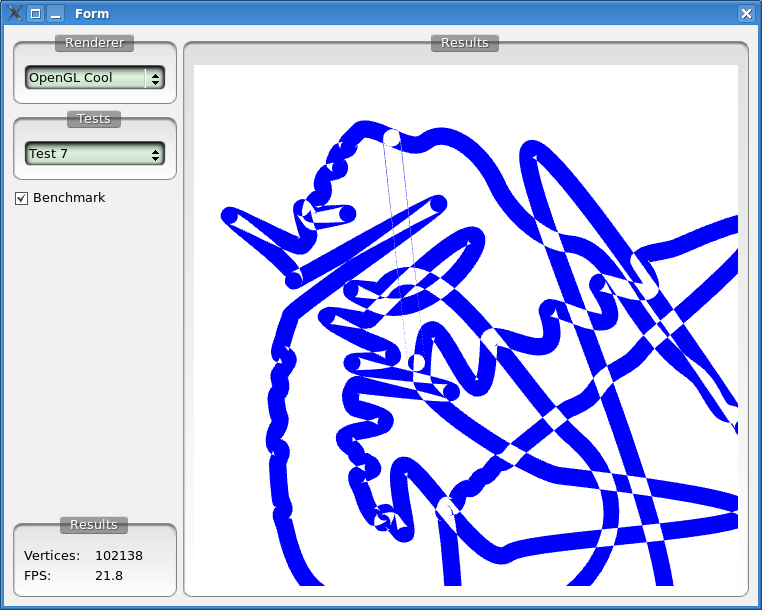
8 comments:
So will this method of drawing be used by default, or only when the paintEngine is a gl based one?
And I have different question, which is a little bit off-topic, but i thought you were the right person to ask: :-)
When the QPaintEngine::OpenGl is used, and an image is being drawn through QPaintEngine::drawImage() is this done with a polygon and the image is applied as texture? (Meaning fully hardware accelerated?)
The reason I'm asking this is, I'm planning to write a 2D-game based on QGraphicsView and many sprites with alpha channel (.png) which should be drawn with full alpha channel onto the view. It would be great if the OpenGL paintEngine would use textures for that, because it should be a lot faster. Or how is the speed of the software paintEngines in this regard? (X11/Windows/CoreGraphics)
Any informtions about that would be highly appreciated!
Zack, the stencil method to draw concave polygons is very old. I first learned about it on the OpenGL programming guide (aka Red Book)
http://fly.srk.fer.hr/~unreal/theredbook/chapter13.html
There also exist similar algorithms for
nonconvex polyhedra, at least when they
are created by Constructive Solid Geometry.
http://www.nigels.com/research/egsggh98.pdf
http://www.cc.gatech.edu/~turk/my_papers/pxpl_csg.pdf
It's great to see good graphics optimisation going on :) But... how will this fare on older hardware (or newer hardware) which doesn't have good accelerated GL?
This approach is really interesting, but...
1. it can't handle correctly the "non-zero" fill rule, but just the "even-odd" one; i'm not sure of this, but i'm thinking on it, and i can't figure out how this approach can handle it.
2. it needs always of a slow double pass technique. It's a limitation in the case of static shapes drawing, or animations throught matrixes, where you can cache the triangles. In a such case (really common, it's the case of an svg viewer, or a vector gui), if you tesselize, just the first frame will be drawn slowly.
3. it fights against the use of the stencil buffer for any other cool thing (e.g: clip-paths, clip-rects)
@ska: like i explained to your on irc none of the things you mentioned is valid. 1) it does handle non-zero rule correctly, 2) you cache the results of a rendering in an offscreen surface if you know it won't change and compose it, 3) you just need to combine it with this approach
Looks like I'm two years late to the discussion, but I'm with ska in not being able to figure out how you could support the "non-zero" fill rule with this technique. It seems that since you are using GL_INVERT for the stencil op, you are inherently tied to "even-odd" fill. You said in your last comment that it could be done; mind explaining? :)
Thanks!
Brad...
I don't know if there is a better way to achieve non-zero "easily" or even if my method really works; but I'm thinking that you could take the winding value of each triangle using an additional pass to do this.
Algorithm follows:
-Set stencil buffer to increment
-Render every clock-wise triangles
-Set stencil buffer to decrement
-Render every counter-clockwise triangles
The remaining set should be such that anything non-zero can be filled without a problem.
It's not as efficient/clean as the even-odd rule (which is maybe why it's rarely talked about); but I believe that this should work
Post a Comment